Countdown Reinforcement Learning (RL)¶
This guide demonstrates reinforcement learning (RL) fine-tuning on the Countdown dataset using a running TuFT server. Full runnable code is in the examples/countdown_rl/countdown_rl.ipynb notebook. Although this is a general RL guide, it also documents common issues users may encounter when using TuFT for RL and provides step-by-step guidance to help them successfully complete an end-to-end run.
What You’ll Learn¶
How to load and split Countdown tasks and turn them into prompt-style problems
How to design a rule-based reward function (format + validity + correctness + optional shaping)
How to run a minimal GRPO-like RL loop in TuFT (group sampling + normalized advantages + importance sampling loss)
How to choose and tune LoRA rank and learning rate using reward curves
Table of Contents¶
Datasets¶
This guide uses Jiayi-Pan/Countdown-Tasks-3to4.
Dataset |
Source |
Typical sample fields |
Use Case |
|---|---|---|---|
Countdown-Tasks-3to4 |
|
|
Verifiable arithmetic expression generation |
Split policy
Test set: first
TEST_SIZErowsTrain set: remaining rows, shuffled with
SEED
This makes runs reproducible and avoids the need for a predefined “test” split.
Minimal Training Example (RL)¶
Unlike the Tinker, TuFT can run on local GPUs; the experiments below were conducted on a local 2× NVIDIA A100-SXM4-80GB setup (Driver 550.54.15, CUDA 12.9). Before running the example, follow the Installation Guide to start the TuFT server locally.
Key TuFT calls (full code in examples/countdown_rl/countdown_rl.ipynb):
import tinker
from tinker import types
service_client = tinker.ServiceClient(base_url=TINKER_BASE_URL, api_key=TINKER_API_KEY)
training_client = service_client.create_lora_training_client(
base_model=BASE_MODEL,
rank=LORA_RANK,
train_mlp=True,
train_attn=True,
train_unembed=True,
)
# RL update uses an importance-sampling style objective:
training_client.forward_backward(datums, loss_fn="importance_sampling").result()
training_client.optim_step(types.AdamParams(learning_rate=LEARNING_RATE)).result()
A practical detail of this RL workflow: each training step exports a sampler-compatible checkpoint, then uses a sampling client to produce rollouts and logprobs for the objective.
Key Concepts¶
Prompting for Verifiable Outputs¶
RL works best when the reward signal is reliable. For Countdown, we enforce a verifiable output contract:
The model must output only a final expression inside:
<answer> ... </answer>A stop sequence
</answer>truncates generation early, reducing junk tokens and reward noise.
A small few-shot example is prepended to improve early training stability (models learn the format faster).
COUNTDOWN_FEWSHOT = (
"Q: Using the numbers 2, 3, 7, reach the target number 13. "
"You may use +, -, *, / and parentheses, and each number can only be used once. "
"Put ONLY the final expression inside <answer>...</answer>. "
"Example: <answer>(1+2)/3</answer>."
"A: <answer>(2*3)+7</answer>"
)
Reward Design: Format, Validity, Correctness, Shaping¶
The reward is intentionally decomposed into stages:
Format reward: output must contain
<answer>...</answer>Validity reward: expression must use exactly the provided numbers (multiset match)
Safe evaluation: expression must be parseable under a restricted grammar/character set
Correctness: evaluated numeric result must match
target
A common RL practice is to include reward shaping to reduce sparsity:
If exact match: reward =
1.0If not exact:
either give only a small constant
FORMAT_SCORE(sparse)or use continuous shaping, e.g.: \(r = r_{\mathrm{fmt}} + \left(1 - r_{\mathrm{fmt}}\right)\frac{1}{1 + \left|y - \mathrm{target}\right|}\)
This provides gradients even when the model is “close but not correct”.
Why the constant FORMAT_SCORE matters
It prevents “all-or-nothing” learning early on.
It encourages the policy to at least satisfy formatting/validity constraints before it can reliably solve the math.
def compute_reward(
response_text: str,
target: int,
nums: list[int],
format_score: float,
use_continuous_shaping: bool,
) -> float:
equation = extract_solution(response_text)
if equation is None:
return 0.0
if not validate_equation(equation, nums):
return float(format_score)
result = evaluate_equation(equation)
if result is None:
return float(format_score)
err = abs(result - target)
if err < 1e-5:
return 1.0
if not use_continuous_shaping:
return float(format_score)
shaped = format_score + (1.0 - format_score) * (1.0 / (1.0 + err))
return float(shaped)
Group Sampling and Normalized Advantages¶
Instead of sampling a single completion per prompt, we sample a group of completions:
For each prompt (problem), sample
GROUP_SIZE = Grollouts.Compute a reward for each rollout.
Then compute within-group statistics:
Within-group mean reward: \(\mu\)
Within-group reward std: \(\sigma\)
Advantages are normalized within the same group:
For sample \(i\): \(A_i=\frac{r_i-\mu}{\sigma+\varepsilon}\)
This is GRPO-like in spirit:
It learns from relative quality among samples from the same prompt (group-wise comparison/ranking).
It reduces the need for a learned value function.
It is sensitive to reward variance: if \(\sigma\) is ~0, the prompt is skipped because there is no useful learning signal.
Intuition
The model is encouraged to increase the probability of rollouts that are better than the group average, and decrease the probability of worse ones.
# Sample GROUP_SIZE completions -> compute rewards -> normalize advantages within the group
res = sampling_client.sample(prompt=prompt, num_samples=GROUP_SIZE,
sampling_params=sampling_params_train).result()
rewards, toks_list, lps_list = [], [], []
for seq in res.sequences:
toks = list(seq.tokens)
lps = list(seq.logprobs) # must be returned by the sampler
text = tokenizer.decode(toks, skip_special_tokens=True)
r = compute_reward(text, target=prob.target, nums=prob.nums,
format_score=FORMAT_SCORE,
use_continuous_shaping=USE_CONTINUOUS_SHAPING)
rewards.append(float(r))
toks_list.append(toks); lps_list.append(lps)
mu = sum(rewards) / len(rewards)
sigma = (sum((r - mu) ** 2 for r in rewards) / len(rewards)) ** 0.5
if sigma < 1e-8:
skipped_problems += 1
continue
advantages = [(r - mu) / (sigma + 1e-6) for r in rewards]
Datum Format for RL¶
Each sampled rollout is converted into a Datum that contains:
model_input: prompt tokens + generated tokens (used as the input sequence for next-token prediction)loss_fn_inputs(extra tensors aligned per token):target_tokens: the next tokens the model should predictlogprobs: behavior-policy (sampling-time) log-probabilities for importance samplingadvantages: per-token weights (typically 0 on the prompt, and a constant advantage on the generated region)
This enables an importance-sampling style objective in token space:
Compare the current policy likelihood to the behavior policy likelihood (from sampling time)
Weight updates by the advantage so higher-reward rollouts are reinforced
ob_len = prompt.length - 1
for toks, lps, adv in zip(tokens_G_T, logprobs_G_T, advantages_G):
model_input = prompt.append(types.EncodedTextChunk(tokens=toks[:-1]))
target_tokens = [0] * ob_len + toks
padded_sampling_logprobs = [0.0] * ob_len + lps
padded_advantages = [0.0] * ob_len + [adv] * (model_input.length - ob_len)
datums_D.append(
types.Datum(
model_input=model_input,
loss_fn_inputs={
"target_tokens": TensorData.from_torch(torch.tensor(target_tokens, dtype=torch.long)),
"logprobs": TensorData.from_torch(torch.tensor(padded_sampling_logprobs, dtype=torch.float32)),
"advantages": TensorData.from_torch(torch.tensor(padded_advantages, dtype=torch.float32)),
},
)
)
Parameter Selection¶
This section explains how to choose lora_rank and learning_rate for the Countdown RL task, and summarizes conclusions based on the provided experiment results. This documentation is based on Qwen/Qwen3-4B-Instruct-2507.
What do lora_rank and learning_rate do?¶
lora_rank (LoRA adapter rank) controls adapter capacity:
Higher rank → more trainable parameters → potentially higher ceiling, but more compute/memory and can be less stable in RL
Lower rank → cheaper and often more stable; usually enough for policy/behavior shaping
learning_rate controls the step size of policy updates:
Too low → slow improvement (under-updating)
Moderate → fast and stable reward gains
Too high → unstable training / reward collapse (over-updating), which is common in RL fine-tuning
Experimental conclusions from the plot¶
Based on Figure 1 (Final Reward vs. Learning Rate for lora_rank ∈ {8, 32, 128}):
Reward increases as LR grows from
1e-6to around1e-4.
All ranks trend upward in this range, indicating the optimizer needs a sufficiently large LR to make meaningful policy progress.The best-performing region is around
5e-5to1e-4.
Final reward peaks near1e-4(and is already strong at5e-5) across ranks. This range is a practical “sweet spot” for stable learning + good performance.Too large LR (
5e-4) causes reward collapse, especially for higher ranks.
At5e-4,lora_rank=32and128drop sharply (near failure), whilerank=8degrades but remains noticeably better. This suggests update instability at overly aggressive LR.Rank has diminishing returns; larger rank is not consistently better.
In the optimal LR region (5e-5–1e-4), ranks8/32/128are relatively close. In this setup, LR is the dominant factor, and increasing rank beyond moderate values does not reliably improve reward.Smaller rank is more forgiving under aggressive learning rates.
When LR is pushed too high,rank=8degrades less thanrank=32/128, indicating better robustness to large updates.
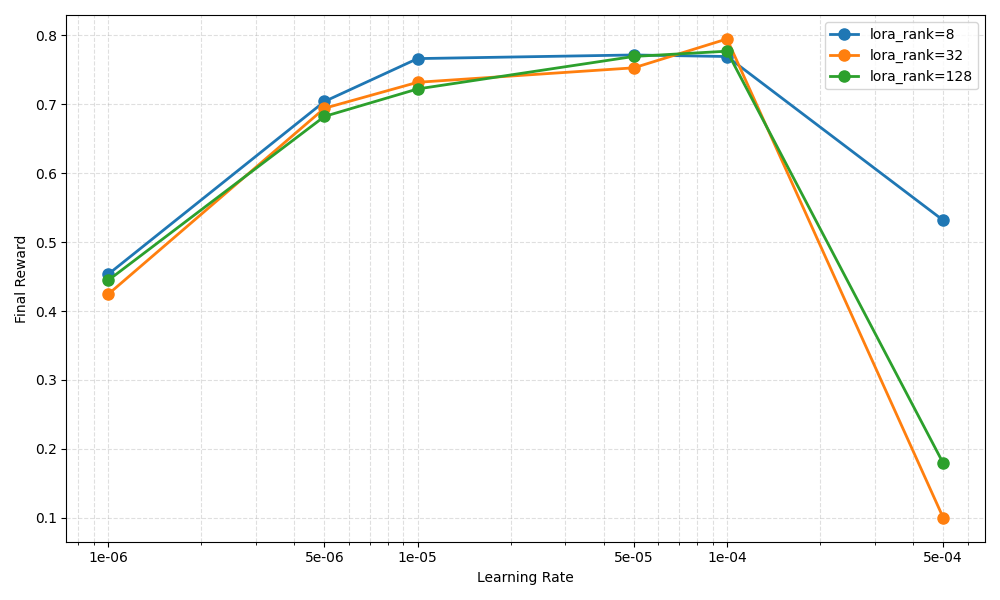
Figure 1. Countdown RL final reward vs. learning rate under different LoRA ranks¶
Practical recommendations¶
Strong default (recommended starting point)
lora_rank = 8 or 32learning_rate = 1e-4
If training is unstable (reward spikes then drops / collapses)
Lower LR first:
1e-4 → 5e-5 → 1e-5If still unstable, lower rank:
32/128 → 8Avoid
5e-4for this setting (Figure 1 shows high collapse risk, especially forrank ≥ 32)
If learning is too slow / reward plateaus
Increase LR gradually toward
5e-5or1e-4Prefer more training steps (and/or stronger stabilization if applicable) before increasing rank
Q&A¶
You can refer to the Q&A section in the Chat SFT Guide. We will also add more RL-related Q&A in the future.